Character Encoding
ASCII and Unicode
All data stored on a computer (number, text, images, sound) needs to be stored as a binary sequence. Depending on the information that the computer is given about the sequence, it will present the data in different ways.
Character Sets
One of the first things that computers were required to process was text. The very first programmable computer Colossus was built with the sole purpose of decrypting messages during World War II. This meant that computer scientists had to come up with a way of converting the letters to numbers so that they could be easily represented by a binary sequence that the computer could use.
Fortunately, there was already several systems in place, including famous examples like the International Telegraph Alphabet No 2 where characters were represented using a sequence of 5 bits, so these were adapted and built on to be used by computers.
The set of characters (letters, numbers, symbols, control characters) that is represented by a specific encoding is known a character set.
ASCII
As computers became more common place in the mid-20th_ century, more and more of these systems were being developed, and it became clear that there was a need for just one system to allow Operating Systems to communicate. In 1963, ASCII (American Standard Code for Information Interchange_) became the standard used by computers.
In ASCII, 7-bits ___were used to represent ___128 different characters.
Here is the ASCII table:
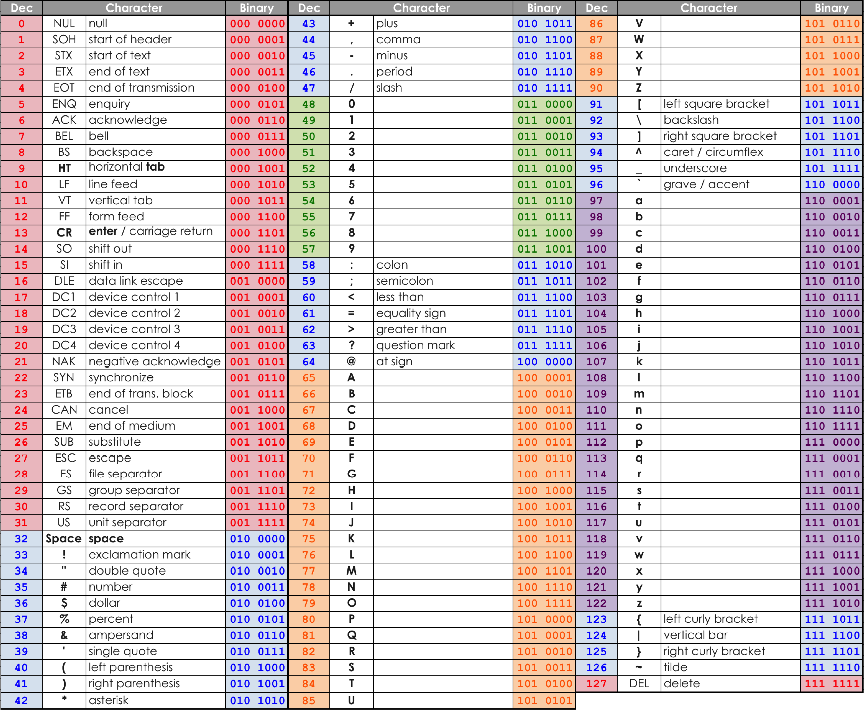
As you can see here, the table appears in several ‘chunks’ separated out by punctuation.
- Numbers 0-31 are for Control Characters (commands that were used in original machines such as backspace or enter)
- Numbers 48 – 57 are numerical digits
- Numbers 65 – 90 are capital letters
- Numbers 97 – 122 are lower case letters
- What is the character code for $? Give your answer in decimal.
- 36
- What is the character code for 4? Give your answer in decimal.
- 52
- What character is represented by the character code 112?
- p
- What character is represented by the character code 43?
- +
Unicode
One of the main issues with ASCII is that it is only able to represent up to___ 128 characters___, which means that it can only be used with the roman (English) alphabet. There are simply not enough bits available to represent all of the characters required to communicate internationally using other languages.
This is when Unicode comes in.
Unicode uses between 1 and 4 bytes to store each character, which means that its character set could potentially contain over 4 billion possible characters. It is backwards compatible with 7-bit ASCII too, so the first 127 characters are still exactly the same. It’s just that in Unicode, additional characters are represented as well.
Another advantage of Unicode is that it can represent far more symbols than __ASCII __can. For example, emoji, which are greatly changing how we communicate.